Wednesday, 6 November 2019
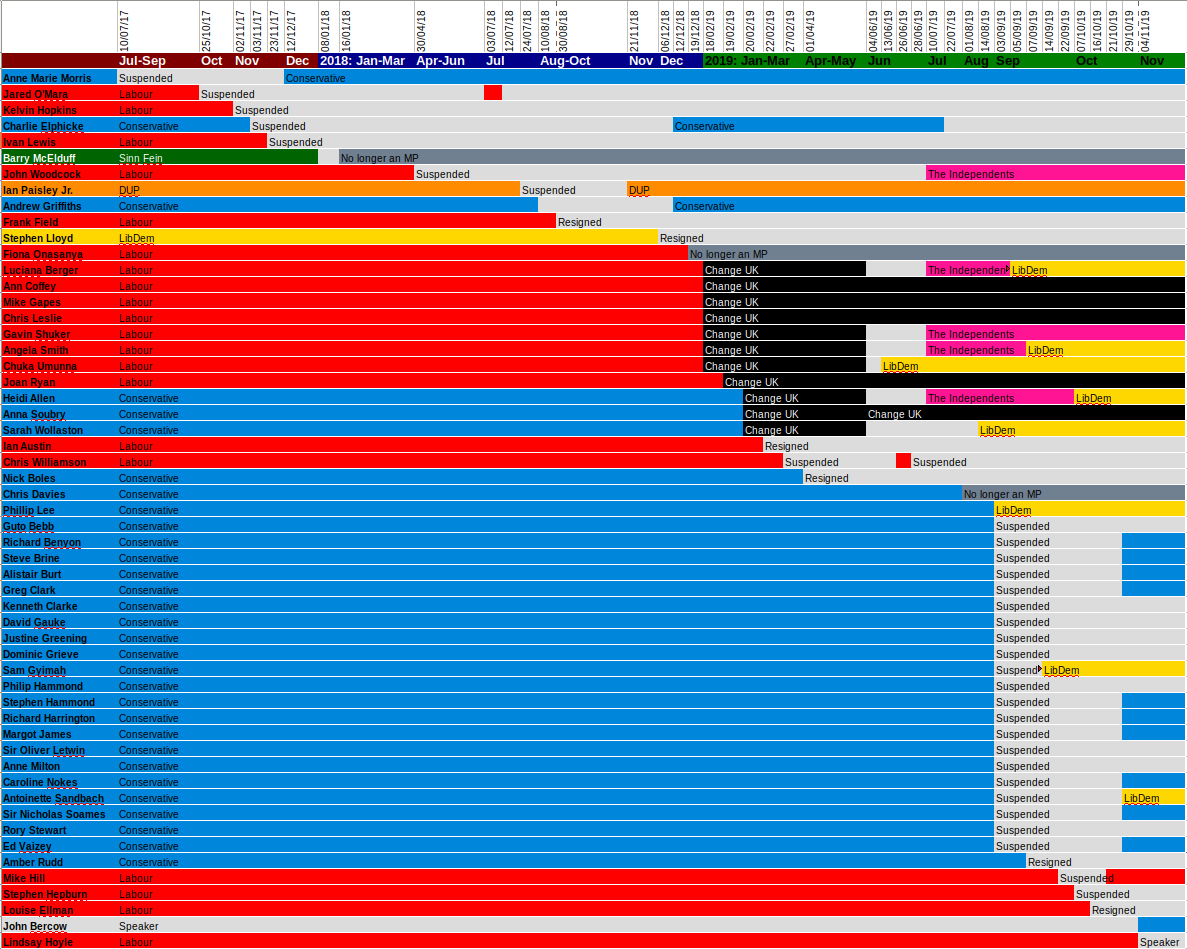
Which MPs changed party affiliation, 2017-2019
Monday, 12 August 2019
In the News: Online Abuse of Politicians, BBC


Tuesday, 30 July 2019
GATE Cloud services for Google Sheets featured in the CLARIN Newsflash
CLARIN ERIC is a research infrastructure through Europe and beyond to encourage the sharing and sustainability of language data and tools for research in the humanities and social sciences. We are pleased to announce that our functions for text analysis in Google Sheets were featured in the July 2019 issue of the CLARIN Newsflash.
We are still working on getting Google to publish our add-on, which we hope to have available in the marketplace in a few months. Until then, you can follow the instructions in our previous blog post to use this tool, which currently provides standard and Twitter-oriented named entity recognition for English, French, and German; named entity linking for English, French, and German; and rumour veracity evaluation for English. In the future we will expand the range of functions to cover a wider variety of GATE Cloud services.
We are still working on getting Google to publish our add-on, which we hope to have available in the marketplace in a few months. Until then, you can follow the instructions in our previous blog post to use this tool, which currently provides standard and Twitter-oriented named entity recognition for English, French, and German; named entity linking for English, French, and German; and rumour veracity evaluation for English. In the future we will expand the range of functions to cover a wider variety of GATE Cloud services.
Monday, 15 July 2019
GATE Cloud services for Google Sheets
Spreadsheets are an increasingly popular way of storing all kinds of information, including text, and giving it some informal structure, and systems like Google Sheets are especially popular for collaborative work and sharing data.
In response to the demand for standard natural language processing (NLP) tasks in spreadsheets, we have developed a Google Sheets add-on that provides functions to carry out the following tasks on text cells using GATE Cloud services:
We have demonstrated this work several times, most recently at the IAMCR conference "Communication, Technology and Human Dignity: Disputed Rights, Contested Truths", which took place on 7–11 July at the Universidad Complutense de Madrid in Spain. There we used it to show how organisations monitoring the safety of journalists could automatically add information about entities and events to their spreadsheets. Potential users have said it looks very useful and they would like access to it as soon as possible.


Open this Google spreadsheet, then use File → Make a copy to save a copy to your own Google Drive (you can’t edit the original). For the functions to work, you will have to grant permission for the scripts to send data to and from GATE Cloud services and to use your user-level cache.
This work has been supported by the European Union’s Horizon 2020 research and innovation programme under grant agreements No 687847 (COMRADES) and No 654024 (SoBigData).
In response to the demand for standard natural language processing (NLP) tasks in spreadsheets, we have developed a Google Sheets add-on that provides functions to carry out the following tasks on text cells using GATE Cloud services:
- named entity recognition (NER) for standard text (e.g. news) in English, French, or German;
- NER tuned for tweets in English, French, or German;
- named entity linking using our YODIE service in English, French, or German;
- veracity reporting for rumours in tweets.
We have demonstrated this work several times, most recently at the IAMCR conference "Communication, Technology and Human Dignity: Disputed Rights, Contested Truths", which took place on 7–11 July at the Universidad Complutense de Madrid in Spain. There we used it to show how organisations monitoring the safety of journalists could automatically add information about entities and events to their spreadsheets. Potential users have said it looks very useful and they would like access to it as soon as possible.

| Google sheet showing Named Entity and Linking applications run over descriptions of journalist killings from the Committee to Protect Journalists (CPJ) databases |
We are applying to have this add-on published in the G Suite Marketplace, but the process is very slow, so we are making the software available now as a read-only Google Drive document that anyone can copy and re-use.
The document contains several examples and instructions are available from the Add-ons → GATE Text Analysis menu item. The language processing is actually done on our servers; the spreadsheet functions send the text to GATE Cloud using the REST API and reformat the output into a human-readable form, so they require a network connection and are subject to rate-limiting. You can use the functions without setting up a GATE Cloud account, but if you create one and authenticate while using this add-on, rate-limiting will be reduced.

Open this Google spreadsheet, then use File → Make a copy to save a copy to your own Google Drive (you can’t edit the original). For the functions to work, you will have to grant permission for the scripts to send data to and from GATE Cloud services and to use your user-level cache.
This work has been supported by the European Union’s Horizon 2020 research and innovation programme under grant agreements No 687847 (COMRADES) and No 654024 (SoBigData).
Friday, 12 July 2019
Using GATE to drive robots at Headstart 2019
In collaboration with Headstart (a charitable trust that provides hands-on science, engineering and maths taster courses), the Department of Computer Science has just run its fourth annual summer school for maths and science A-level students. This residential course ran from 8 to 12 July 2019 and included practical work in computer programming, Lego robots, and project development as well as tours of the campus and talks about the industry.
For the third year in a row, we have included a section on natural language processing using GATE Developer and a special GATE plugin (which uses the ShefRobot library available from GitHub) that allows JAPE rules to operate the Lego robots. As before, we provided the students with a starter GATE application (essentially the same as in last year's course) containing just enough gazetteer entries, JAPE, and sample code to let them tweet variations like "turn left" and "take a left" to make the robot do just that. We also use the GATE Cloud Twitter Collector, which we have modified to run locally so the students can set it up on a lab computer so it follows their own twitter accounts and processes their tweets through the GATE application, sending commands to the robots when the JAPE rules match.

Based on lessons learned from the previous years, we put more effort into improving the instructions and the Twitter Collector software to help them get it running faster. This time the first robot started moving under GATE's control less than 40 minutes from the start of the presentation, and the students rapidly progressed with the development of additional rules and then tweeting commands to their robots.


The structure and broader coverage of this year's course meant that the students had more resources available and a more open project assignment, so not all of them chose to use GATE in their projects, but it was much easier and more streamlined for them to use than in previous years.
This year 42 students (14 female; 28 male) from around the UK attended the Computer Science Headstart Summer School.
 |
| Geography of male students |
 |
| Geography of female students |
The handout and slides are publicly available from the GATE website, which also hosts GATE Developer and other software products in the GATE family. Source code is available from our GitHub site.
GATE Cloud development is supported by the European Union’s Horizon 2020 research and innovation programme under grant agreement No 654024 (the SoBigData project).
Wednesday, 3 July 2019
12th GATE Summer School (17-21 June 2019)
12th GATE Training Course: open-source natural language processing with an emphasis on social media
For over a decade, the GATE team has provided an annual course in using our technology. The course content and track options have changed a bit over the years, but it always includes material to help novices get started with GATE as well as introductory and more advanced use of the JAPE language for matching patterns of document annotations.The latest course also included machine learning, crowdsourcing, sentiment analysis, and an optional programming module (aimed mainly at Java programmers to help them embed GATE libraries, applications, and resources in web services and other "behind the scenes" processing). We have also added examples and new tools in GATE to cover the increasing demand for getting data out of and back into spreadsheets, and updated our work on social media analysis, another growing field.
 |
| Information in "feral databases" (spreadsheets) |
 |
| Semantics in scientometrics |
- From KNOWMAK and RISIS, we presented our work on using semantic technologies in scientometrics, by applying NLP and ontologies to document categorization in order to contribute to a searchable knowledge base that allows users to find aggregate and specific data about scientific publications, patents, and research projects by geography, category, etc.
- Much of our recent work on social media analysis, including opinion mining and abuse detection and measurement, has been done as part of the SoBigData project.
- The increasing range of tools for languages other than English links with our participation in the European Language Grid, which is also supported further development of GATE Cloud, our platform for text analytics as a service.
 |
| Conditional processing of multilingual documents |
 |
| Processing German in GATE |
Acknowledgements
Thursday, 27 June 2019
GATE's submission wins 2nd place in United Nations General Assembly Resolutions Extraction and Elicitation Global Challenge
In May 2019 we submitted a prototype to the United Nations General Assembly Resolutions Extraction and Elicitation Global Challenge, which asked for submissions using mature natural language processing techniques to produce semantically enhanced, machine-readable documents from PDFs of UN GA resolutions, with particular interest in identifying named entities and items in certain thesauri and ontologies and in making use of the document structure (in particular, the distinction between preamble and operative paragraphs).
Our prototype included a customized GATE application designed to read PDFs of United Nations General Assembly resolutions and identify named entities, resolution adoption information (resolution number and adoption date), preamble sections, operative sections, and references to keywords and phrases in the English parts of the UN Bibliographical Information System thesaurus.
We downloaded and automatically annotated over 2800 resolution documents and pushed the results into a Mímir index to allow semantic search using combinations of the entities and sections identified, such as the following (more examples are provided in the documentation that we submitted):
- find sentences in operative paragraphs containing a person and an UNBIS term;
- find preamble paragraphs containing a person, an organization, and a date;
- find combinations referring to a specific UNBIS term.
We also developed an easier to use web front end for exploring co-occurrences of keywords and semantic annotations.




We are excited to receive the second place award, along with an invitation to improve our work with more feedback and a "lessons learned" discussion with the panel. The panel highlighted in particular the submission of comprehensive and testable code, and the use of GATE as a mature respected framework.

Our GitHub site contains the information extraction and search front end software, licensed under the GPL-3.0 and available for anyone to download and use.
Thursday, 6 June 2019
Toxic Online Discussions during the UK European Parliament Election Campaign

The Brexit Party attracted the most engagement on Twitter in the run-up to the UK European Parliament election on May 23rd, their candidates receiving as many tweets as all the other parties combined. Brexit Party leader Nigel Farage was the most interacted-with UK candidate on Twitter, with over twice as many replies as the next most replied-to candidate, Andrew Adonis of the Labour Party.
We studied all tweets sent to or from (or retweets of or by) UK European Election candidates in the month of May, and classified them as abusive or not using the classifier presented here. It must be noted, in particular, that the classifier only identifies reliably whether a reply is abusive or not. It is not sufficiently accurate for us to reliably judge the target politician or party of this abusive reply. What this means is that we can only reliably identify which EP candidates triggered abuse-containing discussion threads on Twitter, but that often this abuse is actually aimed at other politicians or parties.
In addition to attracting the most replies, the Brexit Party candidates also triggered an unusually high level of abuse-containing Twitter discussions. In particular, we found that posts by Farage triggered almost six times as many abuse-containing Twitter threads than the next most replied to candidate, Gavin Esler of Change UK, during May 2019.
There is an important difference, however, in that that many of the abuse-containing replies to posts by Farage and the Brexit Party were actually abusive towards other politicians (most notably the prime minister and the leader of the Labour party) and not Farage himself. In contrast, abusive replies to Gavin Esler were primarily aimed at the politician himself, triggered by his use of the phrase "village idiot" in connection with the Leave Campaign.
Candidates from other parties that triggered unusually high levels of abuse-containing discussions were those from the UK Independence Party, now considered far right, and Change UK, a newly formed but unstable remain party. Change UK was the most active on Twitter, with candidates sending more tweets than other parties. Gavin Esler was the most replied-to Change UK candidate, and also received an unusually high level of abuse. The abuse often referred to his use of the phrase "village idiot" in connection with the leave campaign, which resulted in anger and resentment.
In contrast, MEP candidates from the Conservative and Labour Parties were not hubs of polarised, abuse-containing discussions on Twitter.
What these findings, unsurprisingly, demonstrate is that politicians and parties who themselves use divisive and abusive language, for example, to brand political opponents as “village idiots”, “traitors”, or as “desperate to betray”, are thus triggering the toxic online responses and deep political antagonism that we have witnessed.

MEP candidates from both the Liberal Democrats and the Green Party were also active on Twitter, with the Green MEP candidates second only to Change UK ones for number of tweets sent, but didn't get a lot of engagement in return. The Liberal Democrats in particular received a low number of replies. This may suggest that these parties became the choices of default for a population of discouraged remainers, as both made gains in the election. Both parties attracted a particularly civil tone of reply.
Brexit Party candidates were also the ones that replied most to those who tweeted them, rather than authoring original tweets or retweeting other tweets.
Acknowledgements: Research carried out by Genevieve Gorrell, Mehmet Bakir, and Kalina Bontcheva. This work was partially supported by the European Union under grant agreements No. 654024 SoBigData and No. 825297 WeVerify.
Thursday, 9 May 2019
GATE at World Press Freedom Day
GATE at World Press freedom day: STRENGTHENING THE MONITORING OF SDG 16.10.1
In her role with CFOM (the University's Centre for Freedom of the Media, hosted in the department of Journalism Studies), Diana Maynard travelled to Ethiopia together with CFOM members Sara Torsner and Jackie Harrison to present their research at the World Press Freedom Day Academic Conference on the Safety of journalists in Addis Ababa, on 1 May, 2019. This ongoing research aims to facilitate the comprehensive monitoring of violations against journalists, in line with Sustainable Development Goal (SDG) 16.10.1. This is part of a collaborative project between CFOM and the press freedom organisation Free Press Unlimited, which aims to develop a methodology for systematic data collection on a range of attacks on journalists, and to provide a mechanism for dealing with missing, conflicting and potentially erroneous information.
Discussing possibilities for adopting NLP tools for developing a monitoring infrastructure that allows for the systematisation and organisation of a range of information and data sources related to violations against journalists, Diana proposed a set of areas of research that aim to explore this in more depth. These include: switching to an events-based methodology, reconciling data from multiple sources, and investigating information validity.

Whereas approaches to monitoring violations against journalists traditionally uses a person-based approach, recording information centred around an individual, we suggest that adopting an events-based methodology instead allows for the violation itself to be placed at the centre: ‘by enabling the contextualising and recording of in-depth information related to a single instance of violence such as a killing, including information about key actors and their interrelationship (victim, perpetrator and witness of a violation), the events-based approach enables the modelling of the highly complex structure of a violation. It also allows for the recording of the progression of subsequent violations as well as multiple violations experienced by the same victim (e.g. detention, torture and killing)’.
 |
| Event-based data model from HURIDOCS Source:
|
Another area of research includes possibilities for reconciling information from different databases and sources of information on violations against journalists through NLP techniques. Such methods would allow for the assessment and compilation of partial and contradictory data about the elements constituting a given attack on a journalist. ‘By creating a central categorisation scheme we would essentially be able to facilitate the mapping and pooling of data from various sources into one data source, thus creating a monitoring infrastructure for SDG 16.10.1’, said Diana Maynard. Systematic data on a range of violations against journalists that are gathered in a methodologically systematic and transparent way would also be able to address issues of information validity and source verification: ‘Ultimately such data would facilitate the investigation of patterns, trends and early warnings, leading to a better understanding of the contexts in which threats to journalists can escalate into a killing undertaken with impunity’. We thus propose a framework for mapping between different datasets and event categorisation schemes in order to harmonise information.

In our proposed methodology, GATE tools can be used to extract information from the free text portions of existing databases and link them to external knowledge sources in order to acquire more detailed information about an event, and to enable semantic reasoning about entities and events, thereby helping to both reconcile information at different levels of granularity (e.g. Dublin vs Ireland; shooting vs killing) and to structure information for further search and analysis.

Slides from the presentation are available here; the full journal paper is forthcoming.
The original article from which this post is adapted is available on the CFOM website.
The original article from which this post is adapted is available on the CFOM website.
Wednesday, 17 April 2019
WeVerify: Algorithm-Supported Verification of Digital Content
Announcing WeVerify: a new project developing AI-based tools for computer-supported digital content verification. The WeVerify platform will provide an independent and community driven environment for the verification of online content, to be used to assist journalists in gathering and verifying quickly online content. Prof. Kalina Bontcheva will be serving as the Scientific Director of the project.
Online disinformation and fake media content have emerged as a serious threat to democracy, economy and society. Content verification is currently far from trivial, even for experienced journalists, human rights activists or media literacy scholars. Moreover, recent advances in artificial intelligence (deep learning) have enabled the creation of intelligent bots and highly realistic synthetic multimedia content. Consequently, it is extremely challenging for citizens and journalists to assess the credibility of online content, and to navigate the highly complex online information landscapes.
WeVerify aims to address the complex content verification challenges through a participatory verification approach, open source algorithms, low-overhead human-in-the-loop machine learning and intuitive visualizations. Social media and web content will be analysed and contextualised within the broader online ecosystem, in order to expose fabricated content, through cross-modal content verification, social network analysis, micro-targeted debunking and a blockchain-based public database of known fakes.
A key outcome will be the WeVerify platform for collaborative,
decentralised content verification, tracking, and debunking.
The platform will be open source to engage communities and citizen journalists alongside newsroom and freelance journalists. To enable low-overhead integration with in-house content management systems and support more advanced newsroom needs, a premium version of the platform will also be offered. It will be furthermore supplemented by a digital companion to assist with verification tasks.
Online disinformation and fake media content have emerged as a serious threat to democracy, economy and society. Content verification is currently far from trivial, even for experienced journalists, human rights activists or media literacy scholars. Moreover, recent advances in artificial intelligence (deep learning) have enabled the creation of intelligent bots and highly realistic synthetic multimedia content. Consequently, it is extremely challenging for citizens and journalists to assess the credibility of online content, and to navigate the highly complex online information landscapes.
WeVerify aims to address the complex content verification challenges through a participatory verification approach, open source algorithms, low-overhead human-in-the-loop machine learning and intuitive visualizations. Social media and web content will be analysed and contextualised within the broader online ecosystem, in order to expose fabricated content, through cross-modal content verification, social network analysis, micro-targeted debunking and a blockchain-based public database of known fakes.
 |
| Add caption |
The platform will be open source to engage communities and citizen journalists alongside newsroom and freelance journalists. To enable low-overhead integration with in-house content management systems and support more advanced newsroom needs, a premium version of the platform will also be offered. It will be furthermore supplemented by a digital companion to assist with verification tasks.
Results will be validated by professional journalists and
debunking specialists from project partners (DW, AFP, DisinfoLab), external participants (e.g. members of the First Draft News
network), the community of more than 2,700 users of the InVID verification plugin, and by media literacy, human rights and
emergency response organisations.
The WeVerify website can be found at https://weverify.eu/, and WeVerify can be found on Twitter @WeV3rify!
The WeVerify website can be found at https://weverify.eu/, and WeVerify can be found on Twitter @WeV3rify!
Monday, 11 March 2019
Coming Up: 12th GATE Summer School 17-21 June 2019

No previous experience or programming expertise is necessary, so it's suitable for anyone with an interest in text mining and using GATE, including people from humanities backgrounds, social sciences, etc.
This event will follow a similar format to that of the 2018 course, with one track Monday to Thursday, and two parallel tracks on Friday, all delivered by the GATE development team. You can read more about it and register here. Early bird registration is available at a discounted rate until 1 May.
The focus will be on mining text and social media content with GATE. Many of the hands on exercises will be focused on analysing news articles, tweets, and other textual content.
The planned schedule is as follows (NOTE: may still be subject to timetabling changes).
Single track from Monday to Thursday (9am - 5pm):
- Monday: Module 1: Basic Information Extraction with GATE
- Intro to GATE + Information Extraction (IE)
- Corpus Annotation and Evaluation
- Writing Information Extraction Patterns with JAPE
- Tuesday: Module 2: Using GATE for social media analysis
- Challenges for analysing social media, GATE for social media
- Twitter intro + JSON structure
- Language identification, tokenisation for Twitter
- POS tagging and Information Extraction for Twitter
- Wednesday: Module 3: Crowdsourcing, GATE Cloud/MIMIR, and Machine Learning
- Crowdsourcing annotated social media content with the GATE crowdsourcing plugin
- GATE Cloud, deploying your own IE pipeline at scale (how to process 5 million tweets in 30 mins)
- GATE Mimir - how to index and search semantically annotated social media streams
- Challenges of opinion mining in social media
- Training Machine Learning Models for IE in GATE
- Thursday: Module 4: Advanced IE and Opinion Mining in GATE
- Advanced Information Extraction
- Useful GATE components (plugins)
- Opinion mining components and applications in GATE
- Module 5: GATE for developers
- Basic GATE Embedded
- Writing your own plugin
- GATE in production - multi-threading, web applications, etc.
- Module 6: GATE Applications
- Building your own applications
- Examples of some current GATE applications: social media summarisation, visualisation, Linked Open Data for IE, and more
Hope to see you in Sheffield in June!
Thursday, 7 March 2019
Python: using ANNIE via its web API
GATE Cloud is GATE, the world-leading text-analytics platform, made available on the web with both human user interfaces and programmatic ones.
My name is David Jones and part of my role is to make it easier for you to use GATE. This article is aimed at Python programmers and people who are, rightly, curious to see if Python can help with their text analysis work.
GATE Cloud exposes a web API for many of its services. In this article, I'm going to sketch an example in Python that uses the GATE Cloud API to ANNIE, the English Named Entity Recognizer.

I'm writing in Python 3 using the really excellent requests library.
The GATE Cloud API documentation describes the general outline of using the API, which is that you make an HTTP request setting particular headers.
The full code that I'm using is available on GitHub and is installable and runnable.
A simple use is to pass text to ANNIE and get annotated results back.
In terms of Python:
The Content-Type header is required and specifies the MIME type of the text we are sending. In this case it's text/plain but GATE Cloud supports many types including PDF, HTML, XML, and Twitter's JSON format; details are in the GATE Cloud API documentation.
The default output is JSON and in this case once I've used Python's json.dumps(thing, indent=2) to format it nicely, it looks like this:
The full Python example uses this code to unpick the annotations and display their type and text:
With the text I gave above, I get this output:
The public service has a fairly limited quota, but if you create an account on GATE Cloud you can create an API key which will allow you to access the service with increased quota and fewer limits.
To use your API key, use HTTP basic authentication, passing in the Key ID as the user-id and the API key password as the password. requests makes this pretty simple, as you can supply auth=(user, pass) as an additional keyword argument to requests.post(). Possibly even simpler though is to put those values in your ~/.netrc file (_netrc in Windows):
machine cloud-api.gate.ac.uk
login 71rs93h36m0c
password 9u8ki81lstfc2z8qjlae
The nice thing about this is that requests will find and use these values automatically without you having to write any code.
Go try using the web API now, and let us know how you get on!
My name is David Jones and part of my role is to make it easier for you to use GATE. This article is aimed at Python programmers and people who are, rightly, curious to see if Python can help with their text analysis work.
GATE Cloud exposes a web API for many of its services. In this article, I'm going to sketch an example in Python that uses the GATE Cloud API to ANNIE, the English Named Entity Recognizer.

I'm writing in Python 3 using the really excellent requests library.
The GATE Cloud API documentation describes the general outline of using the API, which is that you make an HTTP request setting particular headers.
The full code that I'm using is available on GitHub and is installable and runnable.
A simple use is to pass text to ANNIE and get annotated results back.
In terms of Python:
text = "David Jones joined the University of Sheffield this year"
headers = {'Content-Type': 'text/plain'}
response = requests.post(url, data=text, headers=headers)
The Content-Type header is required and specifies the MIME type of the text we are sending. In this case it's text/plain but GATE Cloud supports many types including PDF, HTML, XML, and Twitter's JSON format; details are in the GATE Cloud API documentation.
The default output is JSON and in this case once I've used Python's json.dumps(thing, indent=2) to format it nicely, it looks like this:
{The JSON returned here is designed to have a similar structure to the format used by Twitter: Tweet JSON. The outermost dictionary has a text key and an entities key. The entities object is a dictionary that contains arrays of annotations of different types; each annotation being a dictionary with an indices key and other metadata. I find this kind of thing is impossible to describe and impossible to work with until I have an example and half-working code in front of me.
"text": "David Jones joined the University of Sheffield this year",
"entities": {
"Date": [
{
"indices": [
47,
56
],
"rule": "ModifierDate",
"ruleFinal": "DateOnlyFinal",
"kind": "date"
}
],
"Organization": [
{
"indices": [
23,
46
],
"orgType": "university",
"rule": "GazOrganization",
"ruleFinal": "OrgFinal"
}
],
"Person": [
{
"indices": [
0,
11
],
"firstName": "David",
"gender": "male",
"surname": "Jones",
"kind": "fullName",
"rule": "PersonFull",
"ruleFinal": "PersonFinal"
}
]
}
}
The full Python example uses this code to unpick the annotations and display their type and text:
gate_json = response.json()
response_text = gate_json["text"]
for annotation_type, annotations in gate_json["entities"].items():
for annotation in annotations:
i, j = annotation["indices"]
print(annotation_type, ":", response_text[i:j])
With the text I gave above, I get this output:
Date : this yearWe can see that ANNIE has correctly picked out a date, an organisation, and a person, from the text. It's worth noting that the JSON output has more detail that I'm not using in this example: "University of Sheffield" is identified as a university; "David Jones" is identified with the gender "male".
Organization : University of Sheffield
Person : David Jones
Some notes on programming
- requests is nice.
- Content-Type header is required.
- requests has a response.json() method which is a shortcut for parsing the JSON into Python objects.
- the JSON response has a text field, which is the text that was analysed (in my example they are the same, but for PDF we need the linear text so that we can unambiguously assign index values within it).
- the JSON response has an entities field, which is where all the annotations are, first separated and keyed by their annotation type.
- the indices returned in the JSON are 0-based end-exclusive which matches the Python string slicing convention, hence we can use response_text[i:j] to get the correct piece of text.
Quota and API keys
The public service has a fairly limited quota, but if you create an account on GATE Cloud you can create an API key which will allow you to access the service with increased quota and fewer limits.
To use your API key, use HTTP basic authentication, passing in the Key ID as the user-id and the API key password as the password. requests makes this pretty simple, as you can supply auth=(user, pass) as an additional keyword argument to requests.post(). Possibly even simpler though is to put those values in your ~/.netrc file (_netrc in Windows):
machine cloud-api.gate.ac.uk
login 71rs93h36m0c
password 9u8ki81lstfc2z8qjlae
The nice thing about this is that requests will find and use these values automatically without you having to write any code.
Go try using the web API now, and let us know how you get on!
Subscribe to:
Posts (Atom)